Reactive Datalog with Vega
Reactive Datalog?
Yes exactly! We are working on a system, dubbed 3DF for Declarative Differential Dataflow [1] , that has the ability to compile Datalog queries into Differential Dataflows.
Differential Dataflow [2] data-parallel programming framework designed to efficiently process large volumes of data and to quickly respond to arbitrary changes in input collections". It is written and maintained by Frank McSherry.
A unique property of this framework is its ability to incrementally update the state of various operators (think join, group, ...). In other words: A Differential Dataflow is a computation that reacts to incoming changes in a smart and efficient way and propagates any new information correctly. There is quite a lot to it and we defer to Frank's blog for a trove of information on Differential itself.
The system consists of a server written in Rust that takes commands via WebSocket and internally constructs the appropriate dataflows. We've build a client that can compile Datalog queries into query plans that the backend understands.
To clarify, here is a small example: We are interested in all people with a certain name and a certain age. As a Datalog query that may look like this:
[:find ?name ?age
:where
[?e :name ?name]
[?e :age ?age]
[(> ?age 18)]]Now we input some new information (In general that may come from some file, a stream, kafka, datomic, ... you name it):
{:name "Mabel" :age 19}3DF will update us promptly (For how see below):
[[["Mabel" 19] 1]]It tells us that there is new information in the result set of our query. The tuple consisting of "Mabel" 19is the result of our query and the 1is the difference. That means this information is added.
Maybe we realized, that we made a typo and we retract the first information and add a new one: :name "Mabel :age 21". 3DF will promptly tell us
[[["Mabel" 19] -1] [["Mabel" 21] 1]]indicating that now there are new facts in the system. The person with name "Mabel" is not 19 but actually 21. This represents a fact, a statement about our world that is true at a given point in time. Given such differences, Differential Dataflow will only do work proportional to the change itself.
Having 3DF keep track of our changes, we can start looking at ClojureScript and Vega.
Communication
3DF exposes a WebSocket connection over which we can register new Datalog expressions, manage input parameters, send data, and receive updates to our queries, as new data arrives in the system.
Any further communication is build around Clojure's amazing async library. The client code [3] is available for both Clojure & ClojureScript. When connecting to the server, we get a single connection handle:
(def conn (create-conn "ws://127.0.0.1:6262"))It contains one async channel were all outputs are put and one sink to which we can write commands. As we likely will be running more than one query, we want dedicated subscribers for every one of them. For that purpose we use pub/sub from the async library. We partition our results by the name of the query.
A registration will look like the following, with the former query:
(exec! conn (register-query "people-over-18" query))Here people-over-18 is our globally named relation and exec! is a macro that will serialize the output from register-query and write it into the WebSocket.
Vega
Alright. Communication is sorted and we have 3DF running. Now a short look at Vega.
Vega is high-level grammar for visualizations [4]. That means we describe, in a declarative manner, what we want Vega to visualize. Here is an example specification [5] for a bar chart with x values taken from the hour field and y values from sum_passenger:
{:data {:name "passenger"}
:width 1000
:heigt 1500
:mark "bar"
:encoding {:x {:field "hour"
:type "quantitative"
:title "Hour"}
:y {:field "sum_passenger"
:type "quantitative"
:title "# passengers"}}}In contrast to normal Vega specs, we do not specify any data. We will stream it!
Vega offers an embed functionality, which can run arbitrary JavaScript in its callbacks. Well thats exactly the place we will put our communication logic to get new results.
(go-loop []
(when-let [[_ results] (!< source)]
(.. res -view
(change data-name
(.. js/vega changeset
(insert (vega-insert encoding (:insert diffmap)))
(remove (vega-remove encoding (:remove diffmap)))))
(run))
(recur)))As soon as some data arrives in the channel, we take it, process it and call two Vega methods. We create a changeset via the change method, expressing what changes Vega should visualize. The insert takes a vector of tuples indicating new data to insert and the remove takes a function, which will be called on the existing data tuples and returns true for all that are supposed to be removed.
In the end we call run which will execute and render the changes. More on that can be read here [6]. Finally we call the embed method and mount into the DOM.
Running Analytics
Our data set is the publicly available data of NYC cab rides [7]. The dataset contains one single day, these are around 9.000.000 lines of uncompressed csv with a size of 800 MB. We are running 3DF in one thread on my MBP.
Every line describes one cab ride with the following attributes: VendorID, pickup_time, passenger_count, trip_distance. The remaining ones are omitted, as we are not using them. We will simulate streaming this data at 1024 lines per batch.
(exec! conn
(register-source
[:cab/vendor :cab/hour :cab/passenger :cab/distance]
{:CsvFile {:path "DATA_PATH"
:separator ","
:schema [[0 {:Number 0}][1 {:Number 0}] [3 {:Number 0}] [4 {:Number 0}]]}}))Columns from this dataset will always have the namespace cab/ such that we can distinguish them from different sources. The reading of the whole dataset takes around 70 seconds with a batch size of 1024 lines. That is quite long, compared to 25 seconds when we do not batch them with that high of a granularity. That is because we increment the logical timestamp every 1024 lines, causing Differential to do a lot more progress tracking work.
The first thing we look at is quite simple: Number of transported people per hour. Here is the Datalog query:
(def passenger
"Number of transported people per hour"
'[:find ?hour (sum ?passenger)
:with ?e
:where
[?e :cab/passenger ?passenger]
[?e :cab/hour ?hour]])The Vega specs for all queries are here: vega-specs
You'll only see parts of the whole day. 3DF will update us with a quite high frequency. Every update consists of values to be removed and values to be added.
{kind=link}
On the x-axis you see the different hours and the y-axis represent the number of transported passengers. You can see how neatly those bars are growing.
Interactive Queries
Well that has been nice and fun. We can stream results of our computations into Vega and get updated visualizations whenever the result set of our query changes. But this is just the beginning. How about creating an interactive visualization just with 3DF?
For this we will create a new query with an interactive input, allowing our users to see results for specific hours of the day. We will be looking at a query that asks for the number of rides aggregated by trip distance, with all distances rounded to integers.
(def distance-distribution
"Aggregate number of rides for a given distance"
'[:find ?distance (count ?e)
:where
[?e :cab/distance ?distance]
[?e :cab/hour ?hour]]) ; <- we want to control thisWe introduce a new interactive input called :filter/hour.
(exec! conn (create-input :filter/hour))Now we have to adapt the query to make use of this new input. For that we bind input values to the symbol ?hour and then join them with the :cab/hour. This ends up looking like the following:
(def distance-distribution
"Aggregate number of rides for a given distance"
'[:find ?distance (count ?e)
:where
[_ :filter/hour ?hour] ; <- the new input
[?e :cab/distance ?distance]
[?e :cab/hour ?hour]])Now we can start transacting into that input and observe changes to our visualization. In Emacs on the right, we update the hour input.
{kind=link}
We start with the distribution at 9pm, move on to 3am, 6pm, and finally to 11pm. You could also add several different hours to see the distribution for all of them combined. Every addition into :filter/hour input leads the ?hour-join in the distance-distribution query to match all those rows that have the respective :cab/hour value. Retractions work the same but with negative differences and as such lead to data being removed.
Embrace The Change
After spending all day building this wonderful dashboard and computing all these aggregates your boss storms into your office. He informs you that one of the vendors has retracted their data usage consent. We need to remove all of their information asap.
3DF to the rescue. We have a system that is designed to propagate changes efficiently. So lets see how we can solve this.
We'll assume that we have a separate database containing information about the different vendors. Every line in our analytics files contains an id, uniquely identifying these vendors. In our query we would match on these ids, in order to incorporate information from the vendor database
(def passenger
"Number of transported people per hour"
'[:find ?hour (sum ?passenger)
:with ?e
:where
[?e :cab/passenger ?passenger]
[?e :cab/hour ?hour]
[?e :cab/vendor ?id]
[_ :vendor/id ?id]])Now observe what happens to our results as we remove this one vendor from the vendor database.
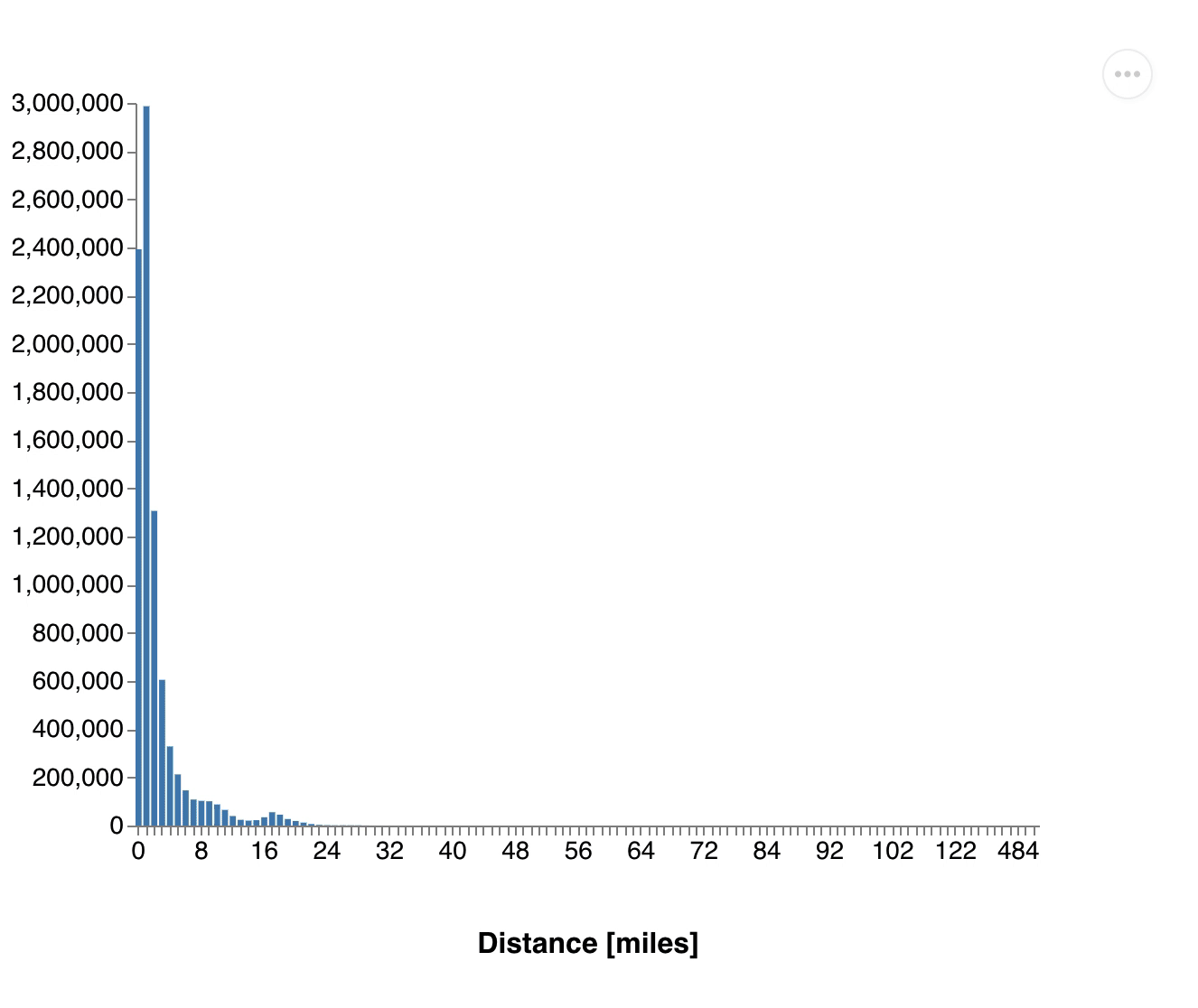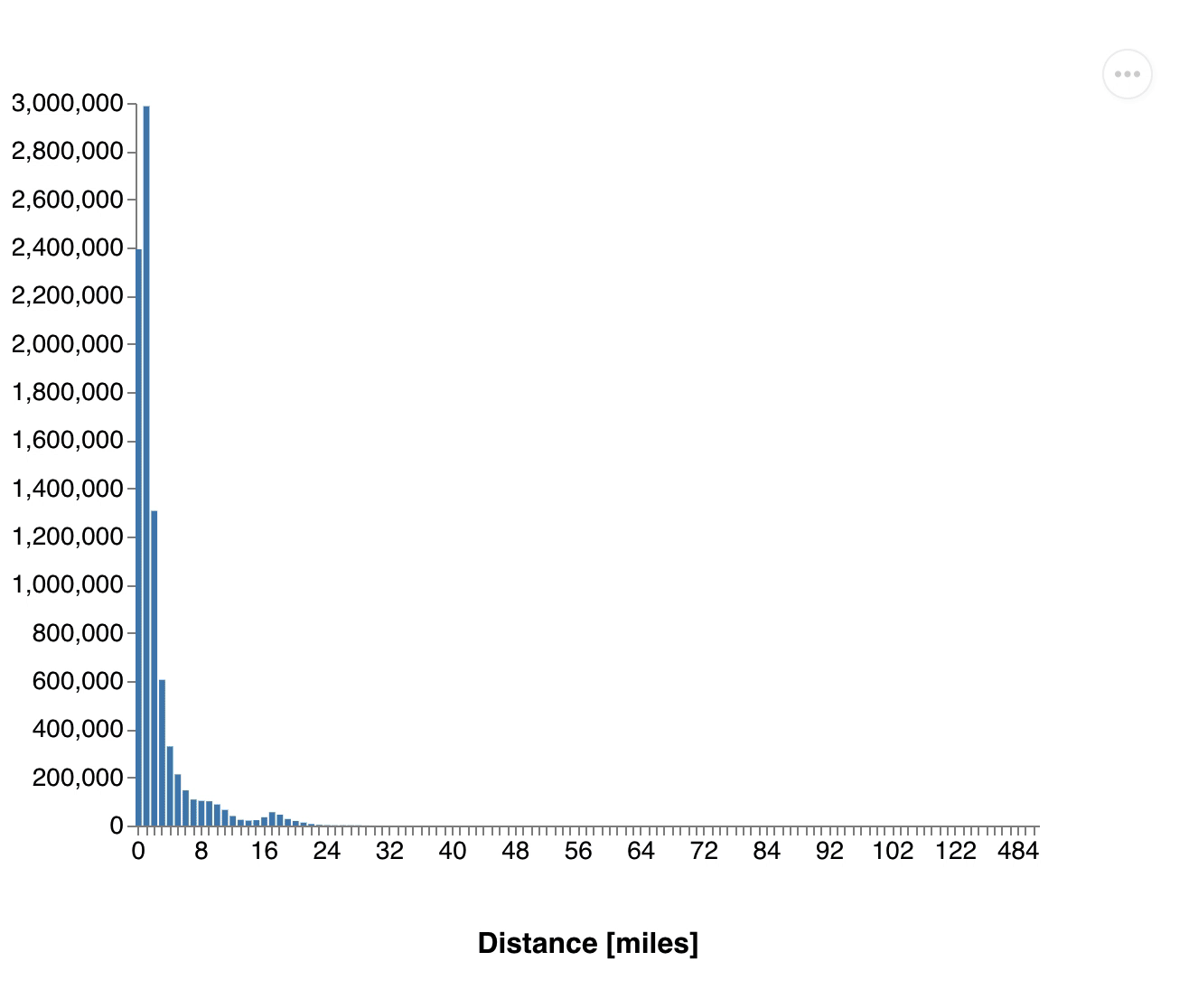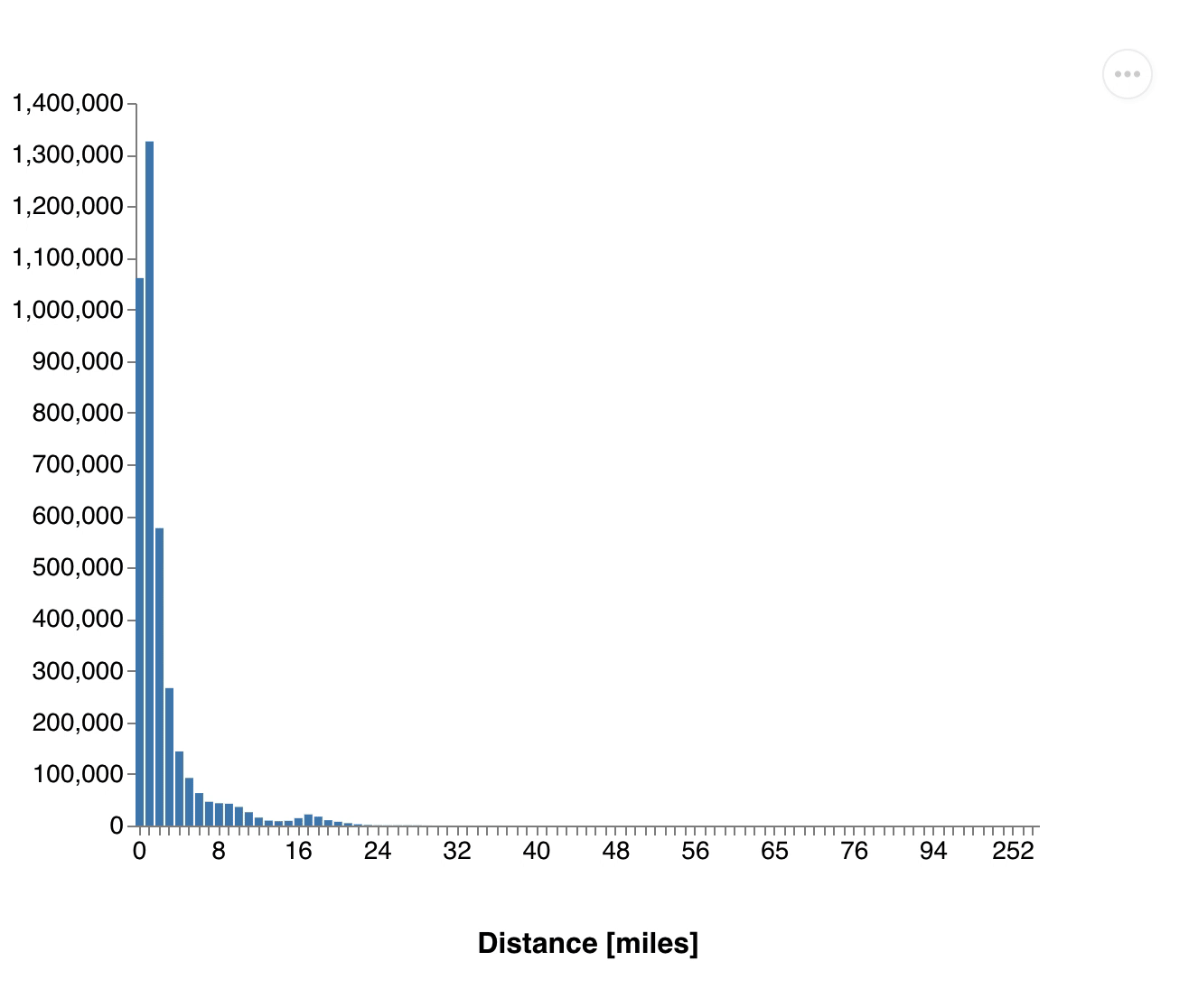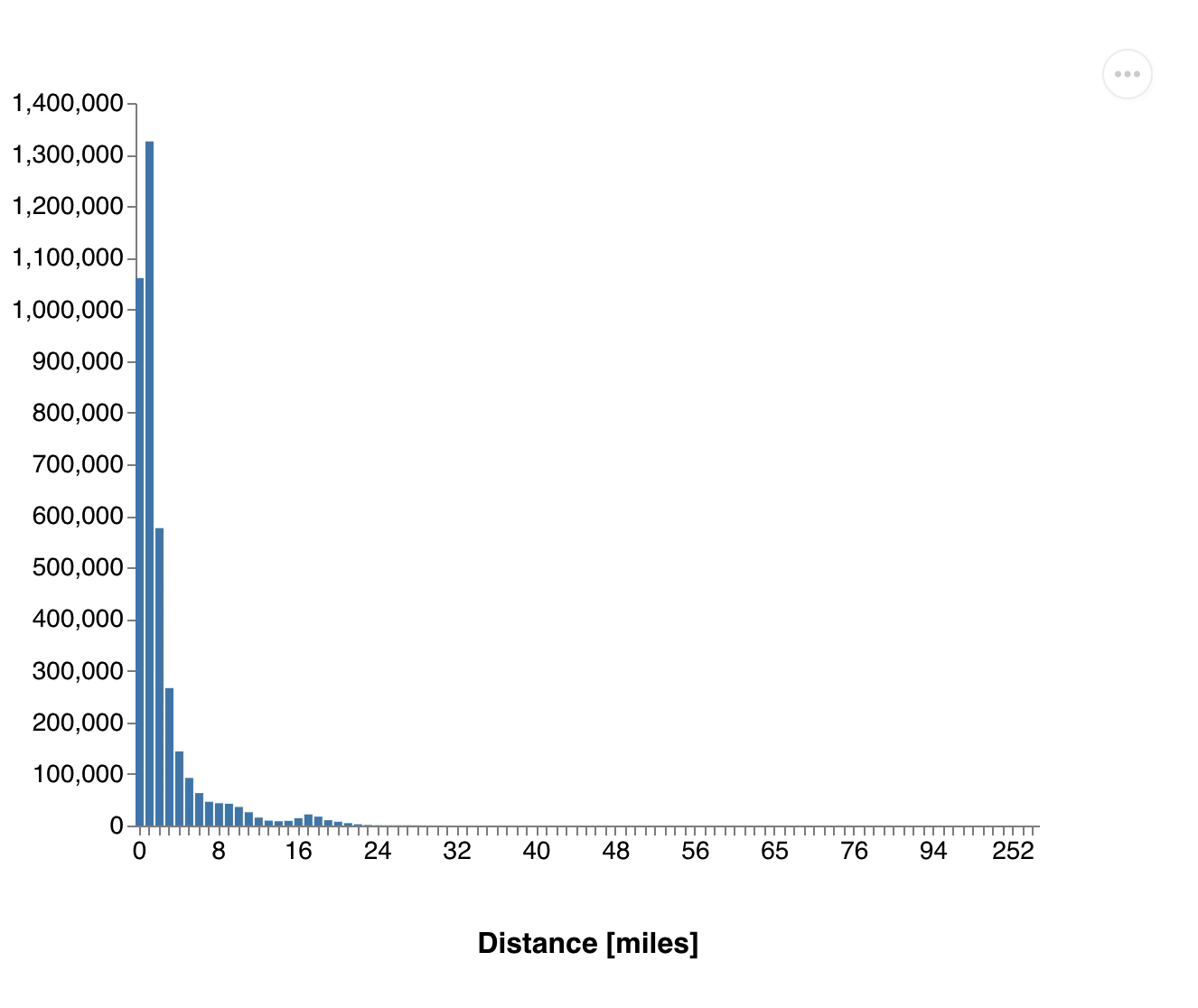
(exec! conn (transact db [[:db/retract :vendor/id 1]]))Number of passenger.gif, Distribution of distances.gif
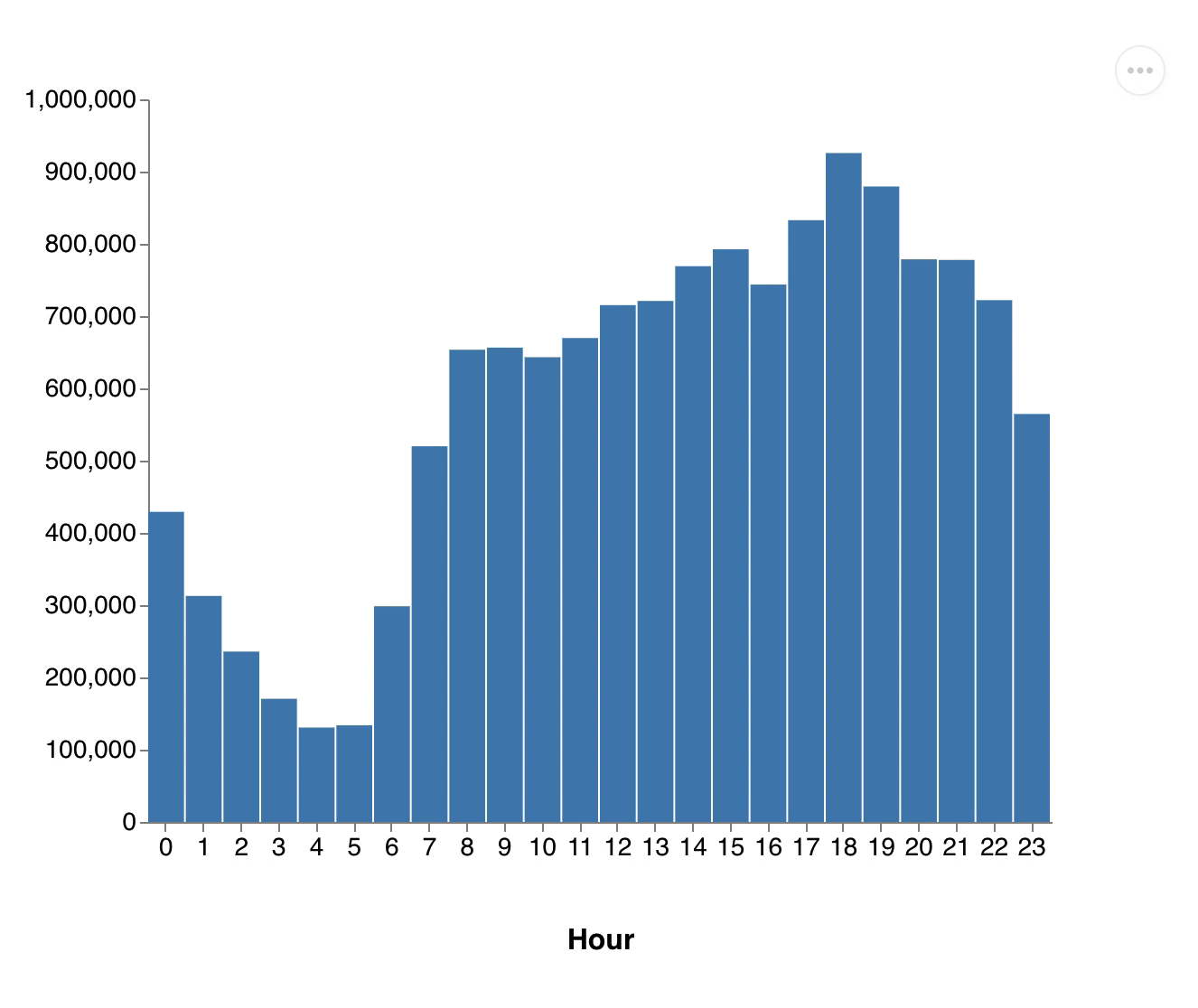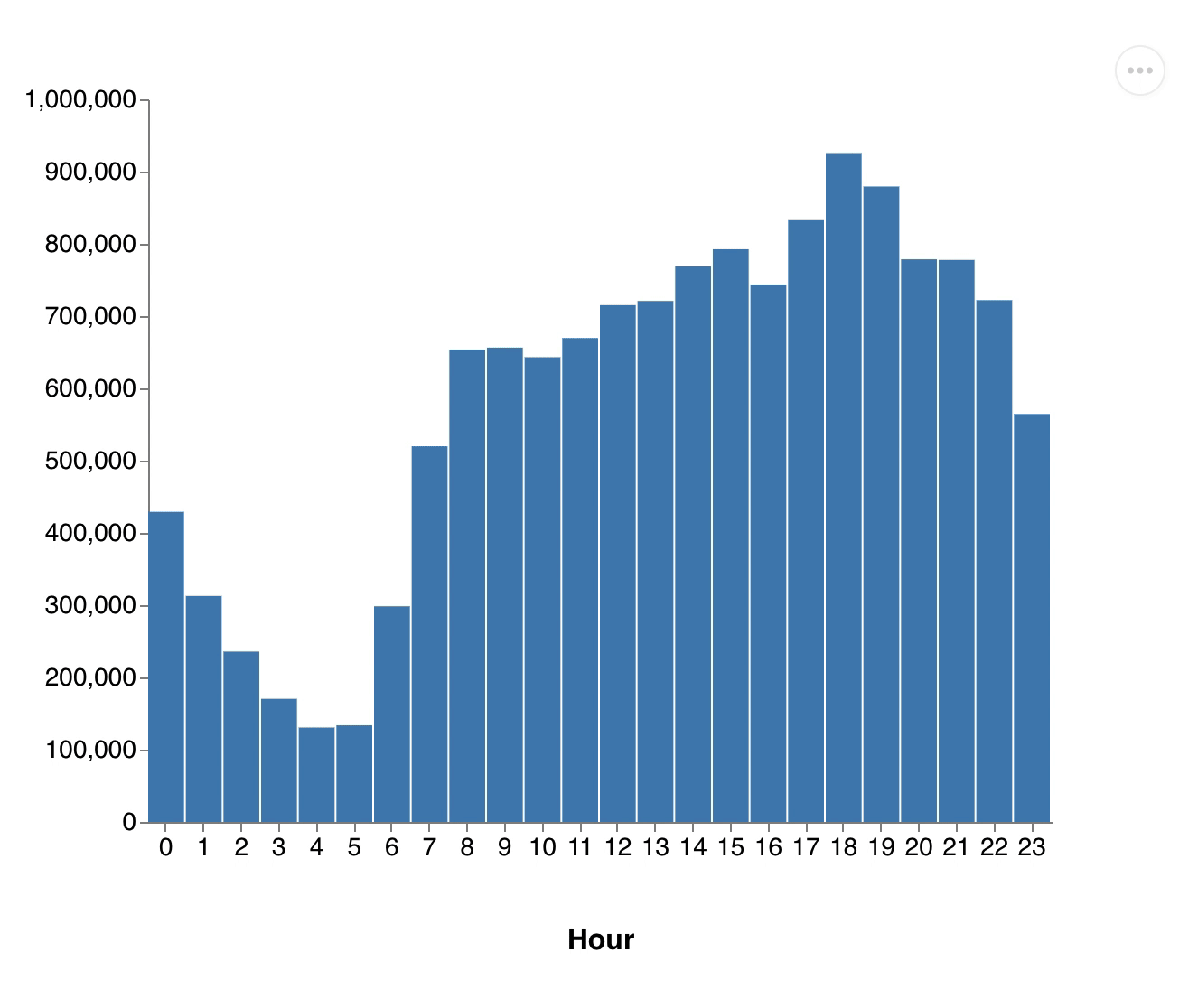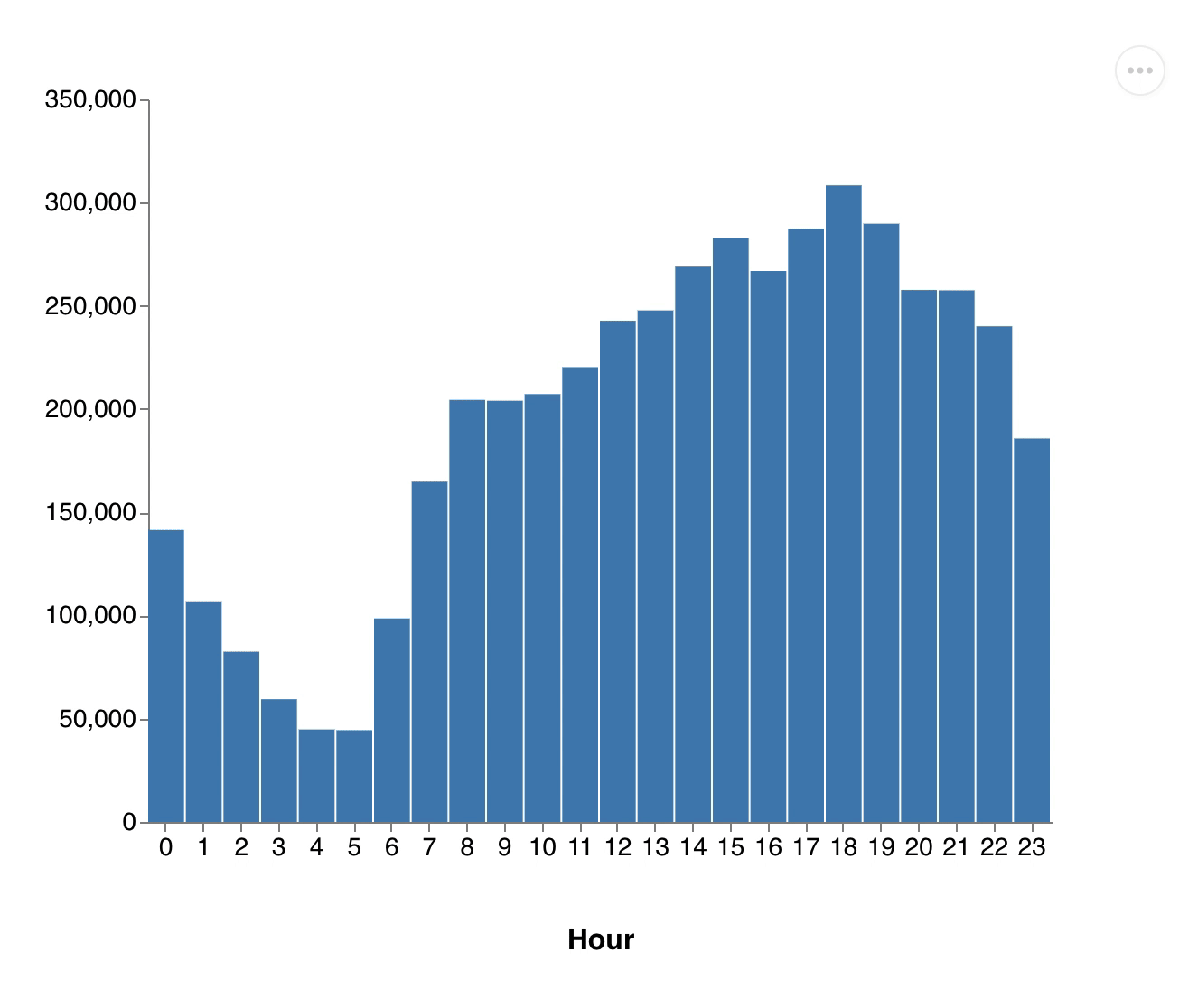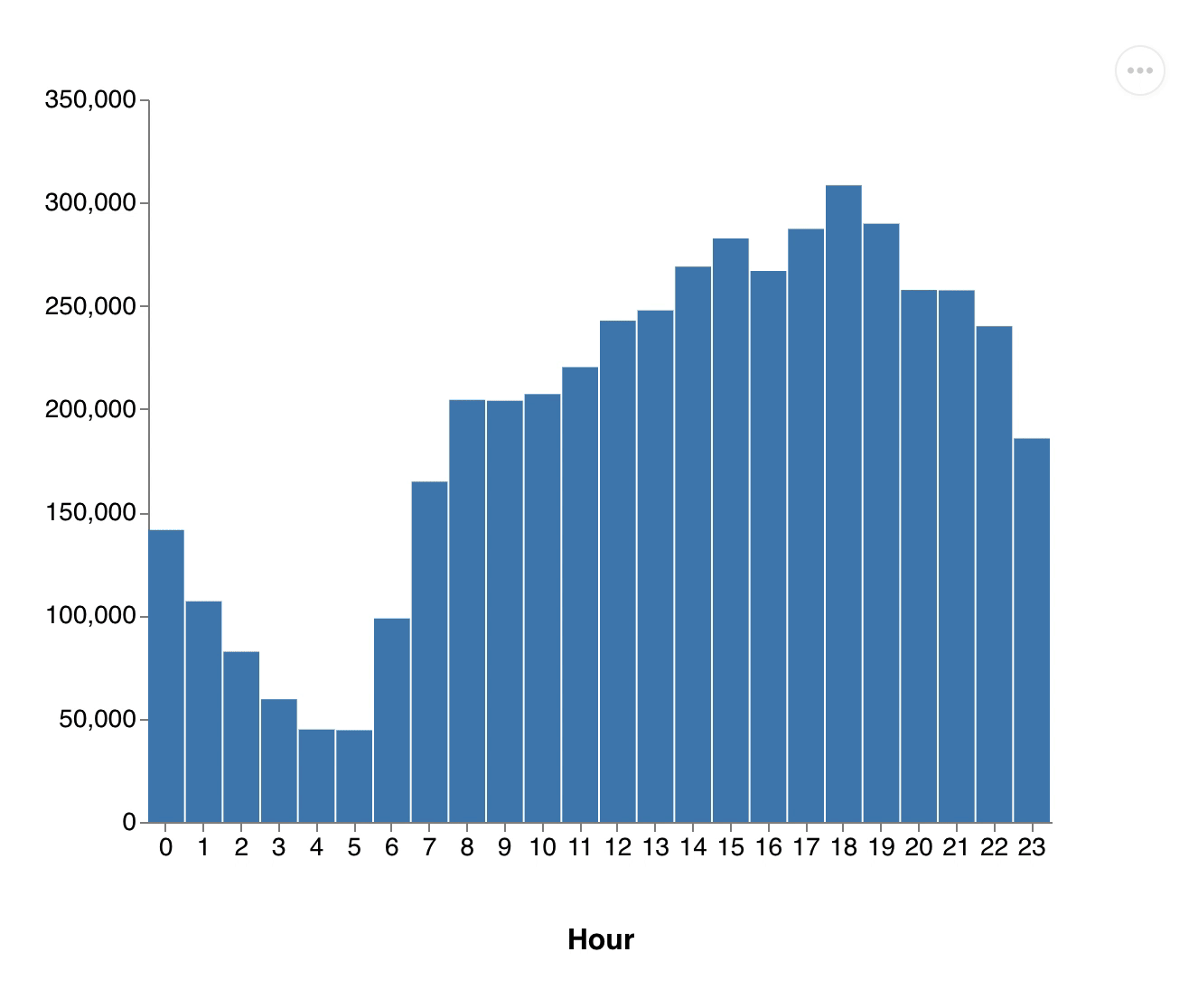{kind=link}
{kind=link}
You see how all the values drop down as we remove the vendor. This one retraction led to a change touching more than half of all cab rides and these changes are propagated through all dataflows.
All our results got updated without us changing our queries or filtering the input dataset. It's also important to note that we didn't have to re-run our computations from scratch, as we can still use the data from all other vendors. 3DF efficiently computed just the differences.
Imagine we had been feeding these results into even more computations, such as price forecasting, movement analytics, or predicting traffic bottlenecks. All those downstream computations might've also used information affected by this retraction, and would now be updated accordingly and in an efficient manner.
Well this has been a lot of fun. Hopefully you've made it through this lengthy piece. Next time we will take a deeper dive into the performance characteristics of working with changes, run computations in a distributed setting, and see how 3DF performs at scale.
Until then cheers and goodbye.
Resources
| [1] | 3DF |
| [2] | Differential Dataflow |
| [3] | clj-3DF |
| [4] | Vega |
| [5] | This is a Vega-lite spec, but all the things we'll see later are Vega. Vega specs are just quite verbose. |
| [6] | Vega-Streaming |
| [7] | NYC Cab Rides |